使用 Knative 在 Google Cloud 上构建事件驱动型图像和 BigQuery 处理管道 ¶
发布时间:2020-07-14 , 修订时间:2024-01-17
使用 Knative 在 Google Cloud 上构建事件驱动型图像和 BigQuery 处理管道¶
作者:Mete Atamel,Google 软件工程师和开发者倡导者
在这篇博文中,我将概述我最近使用 Knative Eventing 构建的两个事件驱动型处理管道。在此过程中,我将解释事件源、自定义事件和 Knative 提供的其他组件,这些组件极大地简化了事件驱动型架构的开发。
这两个管道都可以在 GitHub 上使用,包括源代码、配置和详细说明,作为我 Knative 教程 的一部分。
使用的 Knative 组件¶
在创建这些示例管道时,我依赖于一些 Knative 组件,这些组件极大地简化了我的开发。更具体地说
- 事件源 允许您在集群中读取外部事件。 Knative-GCP 源 提供了许多事件源,可以随时从各种 Google Cloud 源中读取事件。
- 代理和触发器 提供事件传递,而无需生产者或消费者了解事件的路由方式。
- 自定义事件和事件回复:在 Knative 中,所有事件都是 CloudEvents,因此使用标准格式的事件以及各种 SDK 来读取/写入它们非常有用。Knative 支持自定义事件和事件回复。任何服务都可以接收事件,进行一些处理,使用新数据创建自定义事件,然后回复代理,以便其他服务可以读取自定义事件。这在管道中非常有用,其中每个服务都进行一些工作并将消息传递给下一个服务。
图像处理管道¶
在此图像处理管道示例中,用户将图像上传到 Google Cloud 上的存储桶中,使用多个不同的 Knative 服务处理图像,并将处理后的图像保存到输出存储桶中。
我为管道定义了两个要求
- 上传的图像在发送到管道之前会进行过滤。例如,不允许成人主题或暴力图像。
- 管道可以包含任意数量的处理服务,这些服务可以根据需要添加或删除。
架构¶
本节介绍图像处理管道的架构。该管道部署到 Google Cloud 上的 Google Kubernetes Engine (GKE)。
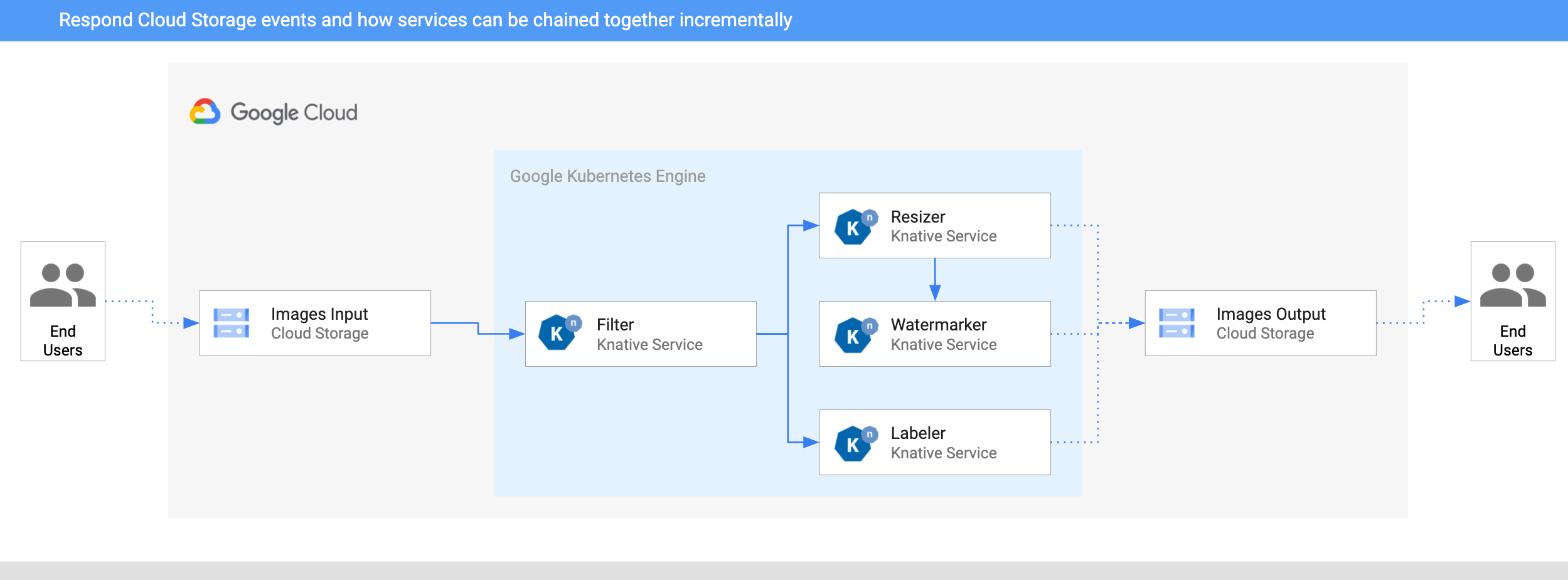
- 图像被保存到输入 Cloud Storage 存储桶中。
- CloudStorageSource 将 Cloud Storage 更新事件读入 Knative。
- 过滤服务接收 Cloud Storage 事件。它使用 Vision API 确定图像是否安全或是否应该被过滤。如果图像安全,过滤服务将创建类型为
dev.knative.samples.fileuploaded的自定义 CloudEvent 并将其传递回代理。 - 调整大小服务接收
fileuploaded事件,然后使用 ImageSharp 库调整图像大小。该服务然后将调整大小后的图像保存到输出存储桶中,创建一个类型为dev.knative.samples.fileresized的自定义 CloudEvent,并将事件传递回代理。 - 水印服务接收
fileresized事件,使用 ImageSharp 库在图像中添加水印,并将图像保存到输出存储桶中。 - 标签器接收
fileuploaded事件,使用 Vision API 从图像中提取标签,并将标签保存到输出存储桶中。
测试管道¶
为了测试管道,我将一张我最喜欢的海滩伊帕内玛在里约热内卢的照片上传到存储桶

几秒钟后,我在输出存储桶中看到了 3 个文件
gsutil ls gs://knative-atamel-images-output
gs://knative-atamel-images-output/beach-400x400-watermark.jpeg
gs://knative-atamel-images-output/beach-400x400.png
gs://knative-atamel-images-output/beach-labels.txt
我们可以在文本文件中看到标签 天空、水体、海洋、自然、海岸、水、日落、地平线、云、海岸,以及调整大小和添加水印后的图像

BigQuery 处理管道¶
此管道示例是一个调度驱动型管道,它查询并找到英国和塞浦路斯每天的 COVID-19 病例数量。我使用了 BigQuery 上的公共 COVID-19 数据集来获取数据,生成图表,并每天给自己发送一封包含这些图表的电子邮件,分别针对每个国家。
架构¶
这是管道的架构。
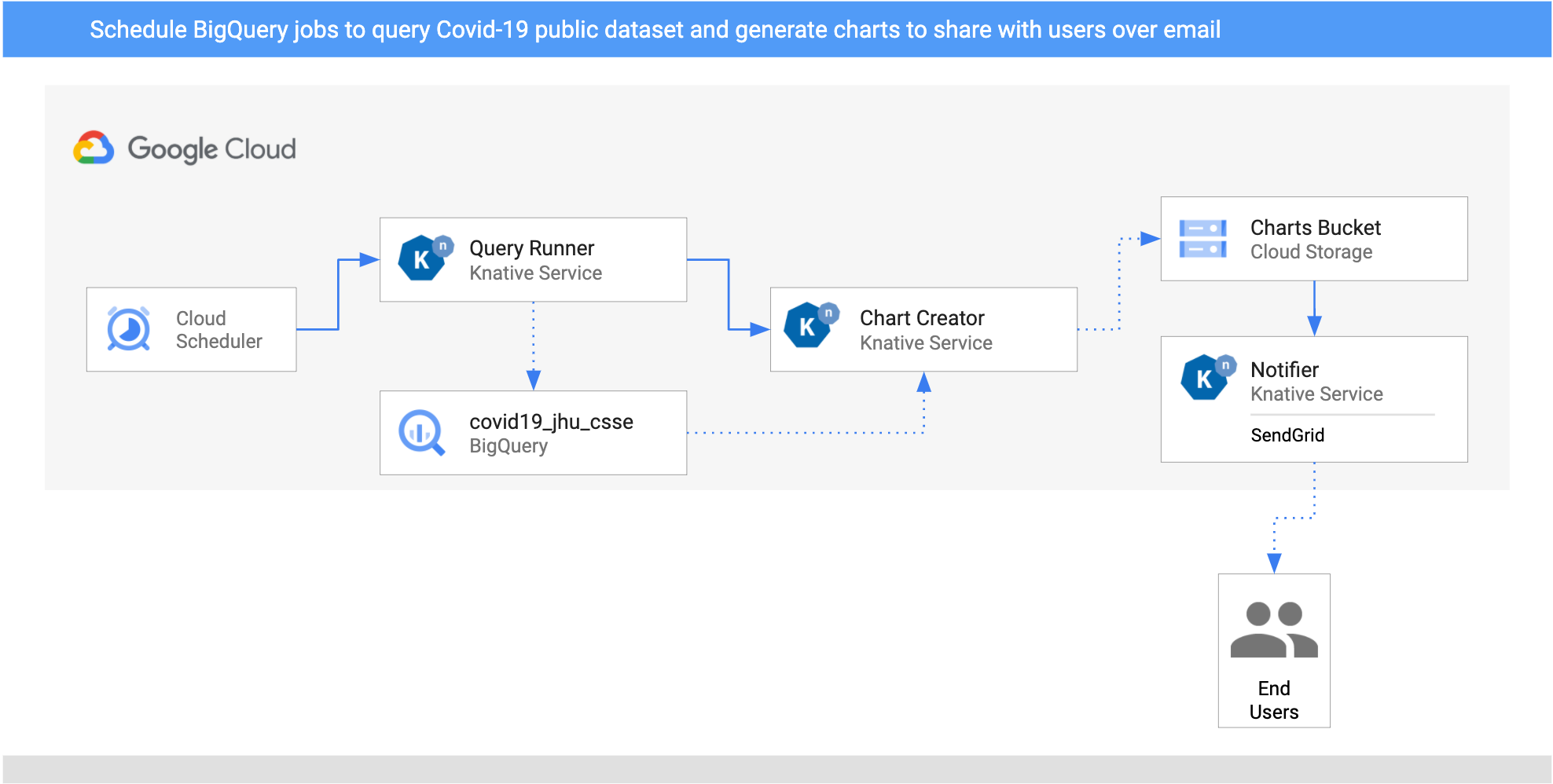
- 我为两个国家(英国和塞浦路斯)设置了两个
CloudSchedulerSources,以每天调用QueryRunner服务一次。 - QueryRunner 服务接收英国和塞浦路斯的调度程序事件,使用 BigQuery 的公共 COVID-19 数据集查询每个国家的 COVID-19 病例,并将结果保存到一个单独的 BigQuery 表中。完成此操作后,QueryRunner 服务将返回一个类型为
dev.knative.samples.querycompleted的自定义 CloudEvent。 - ChartCreator 服务接收
querycompletedCloudEvent,使用Matplotlib从 BigQuery 数据创建图表,并将图表保存到 Cloud Storage 存储桶中。 - 通知服务是另一个接收存储桶中
com.google.cloud.storage.object.finalizeCloudEvent 的服务(通过 CloudStorageSource),并使用 SendGrid 向用户发送电子邮件通知。
测试管道¶
CloudSchedulerSource 创建 CloudScheduler 作业
gcloud scheduler jobs list
ID LOCATION SCHEDULE (TZ) TARGET_TYPE STATE
cre-scheduler-2bcb33d8-3165-4eca-9428-feb99bc320e2 europe-west1 0 16 * * * (UTC) Pub/Sub ENABLED
cre-scheduler-714c0b82-c441-42f4-8f99-0e2eac9a5869 europe-west1 0 17 * * * (UTC) Pub/Sub ENABLED
触发作业
gcloud scheduler jobs run cre-scheduler-2bcb33d8-3165-4eca-9428-feb99bc320e2
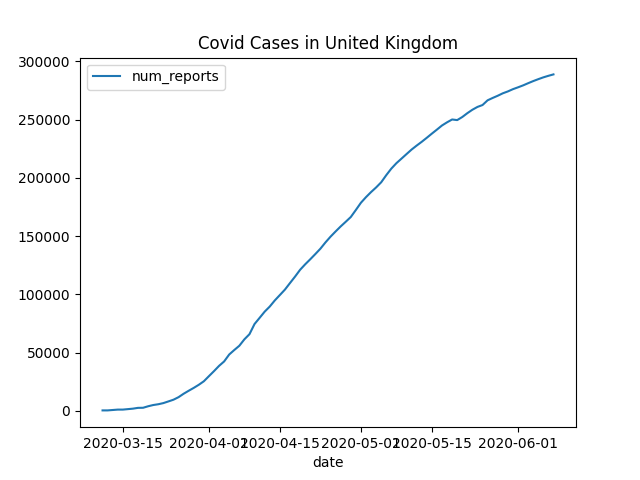
您应该在几分钟内收到一封包含类似于以下图表的电子邮件
这篇博文到此结束。正如我之前提到的,如果你想要更详细的说明,你可以查看我 Knative 教程 中的 image-processing-pipeline 和 bigquery-processing-pipeline。
如果你有任何问题或意见,欢迎在 Twitter 上联系我 @meteatamel)。
作者:Mete Atamel - Google Cloud 开发者布道师