Knative 数据路径上的激活器解析 ¶
发布时间:2024-03-20, 修订时间:2024-03-22
Knative 数据路径上的激活器解析¶
作者:Stavros Kontopoulos,RedHat 首席软件工程师
在本博文中,您将了解如何识别激活器何时位于数据路径上以及是什么触发了这种行为。
Knative 服务在提供流量时可以运行在两种模式下:代理模式和服务模式。在代理模式下,激活器组件位于数据路径上(这意味着传入请求通过激活器路由),并且它将一直停留在路径上,直到满足某些条件(稍后会详细介绍)。如果满足这些条件,激活器将从数据路径中移除,并且服务将过渡到服务模式。例如,当服务从零扩展到零时,激活器默认情况下会添加到数据路径中。这种默认设置经常会让用户感到困惑,因为除非有足够的容量可用,否则激活器将不会从路径中移除。这是有意为之的,因为激活器的作用之一是提供背压功能(充当请求缓冲区),以便 Knative 服务不会被传入流量所淹没。此外,Knative 服务可以使用注释定义它可以处理多少流量。自动扩展器组件将使用此信息来计算处理特定 Knative 服务传入流量所需的 pod 数量。
背景¶
Knative 中的默认 pod 自动扩展器(KPA)是一个复杂的算法,它使用 pod 的指标来做出扩展决策。让我们详细了解一下创建新的 Knative 服务时会发生什么。
一旦用户创建了一个新的服务,相应的 Knative 调解器就会为该服务创建一个 Knative 配置和一个 Knative 路由(有关 Knative K8s 资源的更多信息,请参阅此处)。然后,配置调解器会创建一个修订资源,而该资源的调解器会创建一个PodAutoscaler(PA)资源以及服务的 K8s 部署。路由调解器会创建一个入口资源,该资源将被 Knative net-* 组件获取,这些组件负责在集群中本地以及在集群外部管理流量。
现在,PA 的创建会触发 KPA 调解器,它会经过某些步骤来为修订版设置自动扩展配置
-
创建一个内部 Decider 资源,该资源在
decider.Status.DesiredScale中保存初始期望的扩展量,并通过多扩展器组件设置 pod 扩展器。pod 扩展器每两秒计算一次新的扩展结果,并根据期望的扩展量是否等于 pod 数量来做出决定。如果不是,它将触发 KPA 调解器的新的调解。目标是让 KPA 获取最新的扩展结果。 -
创建一个 Metric 资源,该资源会触发指标收集器控制器为修订版 pod 设置一个抓取器。
-
调用一个扩展方法,该方法会决定所需的 pod 数量,还会更新与修订版相对应的 K8s 原生部署。
-
创建/更新一个
无服务器服务(SKS),它保存有关操作模式(代理或服务)的信息,并存储在代理模式下应使用的激活器数量。SKS 中指定的激活器数量取决于需要覆盖的容量。 -
更新 PA 并报告 PA 状态中的活动 pod 和所需 pod
注意
上面的 SKS 创建/更新事件会触发来自其特定控制器的 SKS 的调解,该控制器会创建所需的公共和私有 K8s 服务,以便流量可以被路由到原生 K8s 部署。此外,在代理模式下,SKS 控制器将获取激活器的数量,并为修订版的公共服务配置相同数量的端点。与 Knative 网络组件完成的网络设置相结合(由 Ingress 资源驱动),这大体上是让 Knative 服务(ksvc)准备好提供流量所需完成的端到端网络设置。Knative 网络组件可以是以下任一组件:net-istio、net-kourier、net-contour 和 net-gateway-api。
实践中的容量和操作模式¶
如前所述,如果可用的容量足够,则激活器将从路径中移除。让我们看看如何计算这种容量,但在那之前,让我们介绍两个概念:恐慌窗口和稳定窗口。恐慌窗口是表示缺乏容量来提供流量的时间段。这通常发生在突然出现流量峰值时。描述何时进入恐慌模式并启动恐慌窗口的条件是
dppc/readyPodsCount >= spec.PanicThreshold
dppc := math.Ceil(observedPanicValue / spec.TargetValue)
dppc代表所需的恐慌 pod 数量,它表示自动扩展器在恐慌模式下需要实现的目标。目标值是自动扩展器所针对的并发利用率,该利用率计算为0.7*(revision_total)。修订版总数是 pod 上允许的扩展指标的最大可能值,默认为 100(容器并发默认值)。0.7 是每个副本的利用率因子,当达到该利用率时,我们需要进行横向扩展。
注意
如果使用 KPA 指标每秒请求数(RPS),那么利用率因子为 0.75。
observedPanicValue是在恐慌窗口期间计算出的并发指标的平均值。恐慌阈值是可配置的(默认为 2),它表示所需 pod 与可用 pod 之比。
在进入恐慌模式后,为了退出,我们需要在等于稳定窗口大小的时期内拥有足够的容量。这也意味着自动扩展器将尝试准备足够的 pod 来增加容量。此外,请注意,在恐慌模式之外运行时,自动扩展器不会使用dpcc,而是使用类似的量:dspc := math.Ceil(observedStableValue / spec.TargetValue),该量基于稳定时期内的指标。
为了量化足够容量的概念并处理流量峰值,我们引入了必须为非负值的过量突发容量 (EBC) 的概念。它定义为
EBC = TotalCapacity - ObservedPanicValue - TargetBurstCapacity.
TotalCapacity 计算为 ready_pod_count*revision_total。默认的 TargetBurstCapacity (TBC) 设置为 200。
此时,我们可以正式定义基于哪个激活器从路径中删除的条件。
重要
如果 EBC >=0,则我们有足够的容量来服务流量,激活器将从路径中删除。
现在,有了上述默认值,并且考虑到请求需要在一段时间内保持在周围才能使并发指标显示出足够的时间段内的负载,这意味着您无法通过请求快速完成的 hello-world 示例获得 EBC>=0。后者对于新手来说通常令人困惑,因为它看起来 Knative 服务从未进入服务模式。在下一个示例中,我们将展示一个也进入服务模式的 Knative 服务的生命周期以及 EBC 如何在实践中计算。此外,该示例使用一个示例应用程序来控制请求通过休眠操作保持的时间,请参阅部分 Autoscale 示例应用程序 - Go。因此,以下是具有 10 个目标并发值和 tbc=10 的示例服务的代码。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: autoscale-go
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "10"
autoscaling.knative.dev/target-burst-capacity: "10"
spec:
containers:
- image: ghcr.io/knative/autoscale-go:latest
我们将演示的场景是部署 ksvc,让它缩放到零,然后发送 10 分钟的流量。然后,我们从自动缩放器收集日志并可视化 EBC 值、准备好的 pod 以及随着时间的推移发生的恐慌模式。图表如下所示。
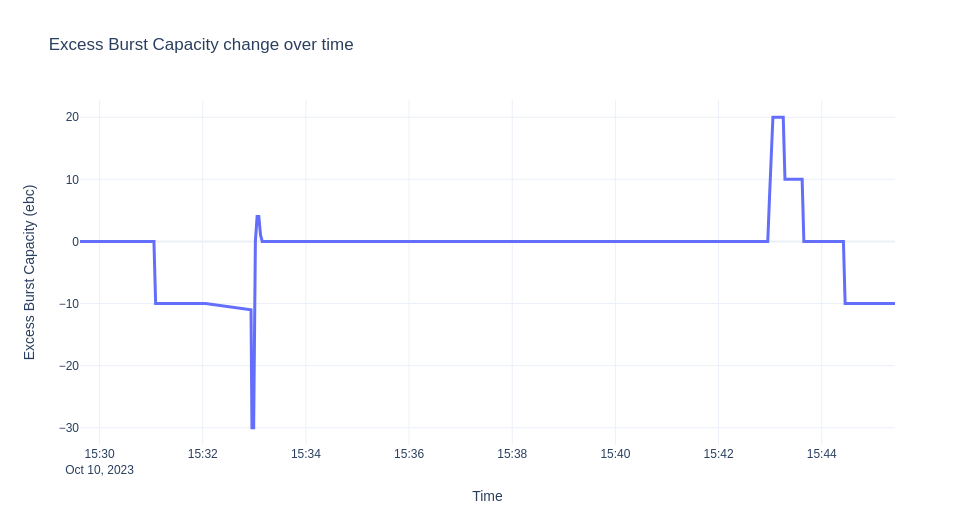
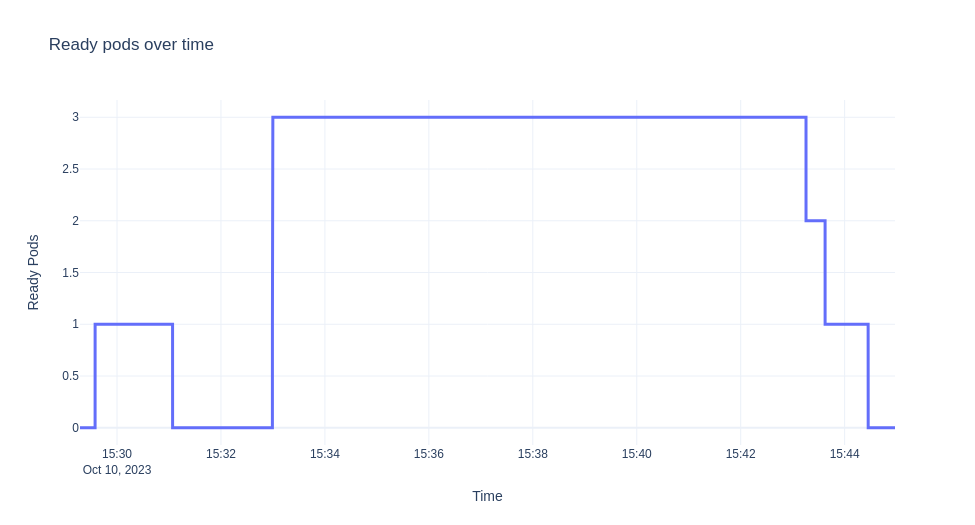
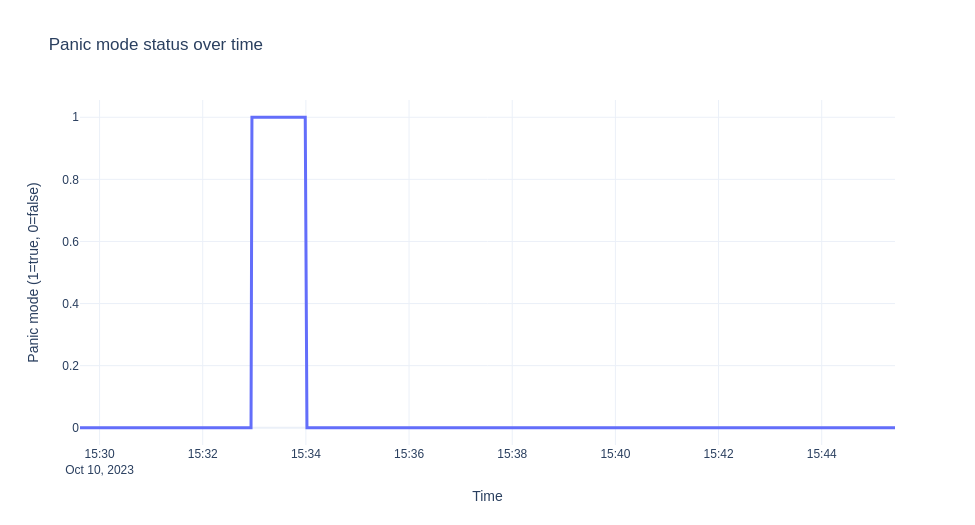
注意
实验在 Minikube 上运行,并使用 hey 工具生成流量。
让我们详细描述一下我们在上面看到的。最初,当 ksvc 部署时,没有流量,并且默认情况下会创建一个 pod 用于验证目的。
在 pod 启动之前,我们有
$ kubectl get sks
NAME MODE ACTIVATORS SERVICENAME PRIVATESERVICENAME READY REASON
autoscale-go-00001 Proxy 2 autoscale-go-00001 autoscale-go-00001-private Unknown NoHealthyBackends
$ kubectl get po
NAME READY STATUS RESTARTS AGE
autoscale-go-00001-deployment-6cc679b9d6-xgrkf 2/2 Running 0 24s
$ kubectl get sks
NAME MODE ACTIVATORS SERVICENAME PRIVATESERVICENAME READY REASON
autoscale-go-00001 Serve 2 autoscale-go-00001 autoscale-go-00001-private True
我们处于服务模式的原因是因为 EBC=0。当您启用调试日志时,您将在日志中获得
...
"timestamp": "2023-10-10T15:29:37.241575214Z",
"logger": "autoscaler",
"message": "PodCount=1 Total1PodCapacity=10.000 ObsStableValue=0.000 ObsPanicValue=0.000 TargetBC=10.000 ExcessBC=0.000",
EBC = 10 - 0 - 10 = 0
请注意,由于没有流量,我们在恐慌或稳定窗口期间没有观察到任何情况。
由于没有流量,我们缩减回零,sks 恢复到代理模式。
$ kubectl get sks
NAME MODE ACTIVATORS SERVICENAME PRIVATESERVICENAME READY REASON
autoscale-go-00001 Proxy 2 autoscale-go-00001 autoscale-go-00001-private Unknown NoHealthyBackends
让我们发送一些流量。
hey -z 600s -c 20 -q 1 -host "autoscale-go.default.example.com" "http://192.168.39.43:32718?sleep=1000"
最初,当激活器接收请求时,它会将统计信息发送到自动缩放器,自动缩放器尝试根据一些初始缩放(默认值为 1)从零开始缩放。
...
"timestamp": "2023-10-10T15:32:56.178498172Z",
"logger": "autoscaler.stats-websocket-server",
"caller": "statserver/server.go:193",
"message": "Received stat message: {Key:default/autoscale-go-00001 Stat:{PodName:activator-59dff6d45c-9rdxh AverageConcurrentRequests:1 AverageProxiedConcurrentRequests:0 RequestCount:1 ProxiedRequestCount:0 ProcessUptime:0 Timestamp:0}}",
"address": ":8080"
自动缩放器进入恐慌模式,因为我们没有足够的容量,EBC 为 10*0 -1 -10 = -11。
...
"timestamp": "2023-10-10T15:32:56.178920551Z",
"logger": "autoscaler",
"caller": "scaling/autoscaler.go:286",
"message": "PodCount=0 Total1PodCapacity=10.000 ObsStableValue=1.000 ObsPanicValue=1.000 TargetBC=10.000 ExcessBC=-11.000",
"timestamp": "2023-10-10T15:32:57.24099875Z",
"logger": "autoscaler",
"caller": "scaling/autoscaler.go:215",
"message": "PANICKING."
...
"timestamp":"2023-10-10T15:32:56.949001622Z",
"logger":"autoscaler.stats-websocket-server",
"message":"Received stat message: {Key:default/autoscale-go-00001 Stat:{PodName:activator-59dff6d45c-9rdxh AverageConcurrentRequests:18.873756322609804 AverageProxiedConcurrentRequests:0 RequestCount:19 ProxiedRequestCount:0 ProcessUptime:0 Timestamp:0}}",
"address":":8080"
...
"timestamp":"2023-10-10T15:32:56.432854252Z",
"logger":"autoscaler",
"caller":"kpa/kpa.go:188",
"message":"Observed pod counts=kpa.podCounts{want:1, ready:0, notReady:1, pending:1, terminating:0}",
...
"timestamp":"2023-10-10T15:32:57.241052566Z",
"logger":"autoscaler",
"message":"PodCount=0 Total1PodCapacity=10.000 ObsStableValue=19.874 ObsPanicValue=19.874 TargetBC=10.000 ExcessBC=-30.000",
考虑到新的统计信息,kpa 决定在某个时间点缩放到 3 个 pod。
"timestamp": "2023-10-10T15:32:57.241421042Z",
"logger": "autoscaler",
"message": "Scaling from 1 to 3",
但让我们看看为什么会出现这种情况。上面的日志来自多缩放器,它报告了一个已缩放的结果,其中包含上面报告的 EBC 和不同窗口的所需 pod 数量。
最终的所需数量大致从我们之前看到的 dppc 中推导出来(还有更多逻辑涵盖极端情况并针对最小/最大缩放限制进行检查)。
在这种情况下,目标值为 0.7*10=10。因此,例如对于恐慌窗口:dppc=ceil(19.874/7)=3。
随着指标稳定下来,修订版也已足够缩放,我们有
"timestamp": "2023-10-10T15:33:01.320912032Z",
"logger": "autoscaler",
"caller": "kpa/kpa.go:158",
"message": "SKS should be in Serve mode: want = 3, ebc = 0, #act's = 2 PA Inactive? = false",
...
"logger": "autoscaler",
"caller": "scaling/autoscaler.go:286",
"message": "PodCount=3 Total1PodCapacity=10.000 ObsStableValue=16.976 ObsPanicValue=15.792 TargetBC=10.000 ExcessBC=4.000",
EBC = 3*10 - floor(15.792) - 10 = 4
然后,当我们达到所需的 pod 数量且指标稳定时,我们得到
"timestamp": "2023-10-10T15:33:59.24118625Z",
"logger": "autoscaler",
"message": "PodCount=3 Total1PodCapacity=10.000 ObsStableValue=19.602 ObsPanicValue=19.968 TargetBC=10.000 ExcessBC=0.000",
几秒钟后,在我们进入恐慌模式后一分钟,我们进入了稳定模式(非恐慌模式)。
"timestamp": "2023-10-10T15:34:01.240916706Z",
"logger": "autoscaler",
"message": "Un-panicking.",
"knative.dev/key": "default/autoscale-go-00001"
sks 也过渡到 serve 模式,因为我们有足够的容量,直到流量停止并且部署缩减回零(激活器从路径中删除)。对于上面的实验,由于我们有近 10 分钟的稳定流量,因此一旦我们有足够的 pod 就绪,我们就不会观察到任何变化。请注意,当流量下降,并且在我们调整 pod 数量之前,在很短的时间内,我们有比需要的更多的 ebc。
以下时间轴也显示了主要事件
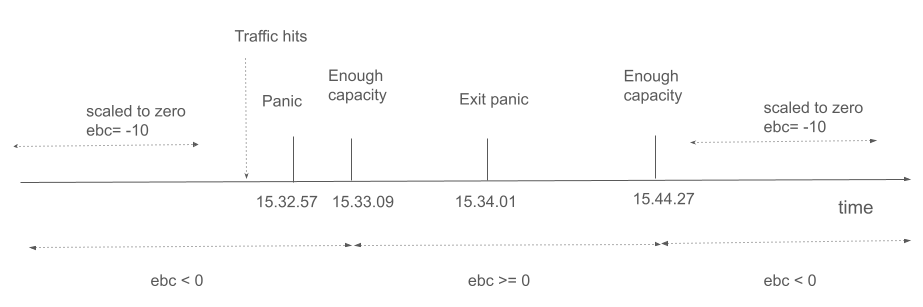
结论¶
服务如何以及为什么卡在代理模式或用户如何在激活器位于数据路径上时管理激活器通常令人困惑。这很重要,尤其是在您刚开始使用 Knative Serving 时。有了上面的详细示例,希望我们已经揭开了 Serving 数据平面的这种基本行为的神秘面纱。